Эта статья будет касаться настройки табуляции в Sublime Text. Первый вопрос - а для чего это нужно и что не устраивает в настройках редактора по умолчанию? На эти два вопроса у меня есть два ответа.
Первое - при общении на форуме верстальщиков было высказывание, что при создании HTML-кода желательно заменить символы табуляции на символы пробела. К примеру, 1
Tab
1
4
1
4
1
Tab
1
2
1
2
Насколько я могу помнить, такое требование небезосновательно, ибо существуют рекомендации Google Руководство по оформлению HTML/CSS кода от Google, в которых упоминается данный вопрос.
Второе - изменить размер табуляции можно и нужно в случае, когда HTML-код большой. При 1
Tab
1
4
Я нахожу такое объяснение (и это мое личное предпочтение) данному вопросу. Итак, приступим к рассмотрению, как настраивается отступы и табуляции в Sublime Text.
Один способ - это не лезть в настройки программы, а воспользоваться ее интерфейсом, который достаточно богат и удобен в этом плане. Рассмотрим картинку ниже:
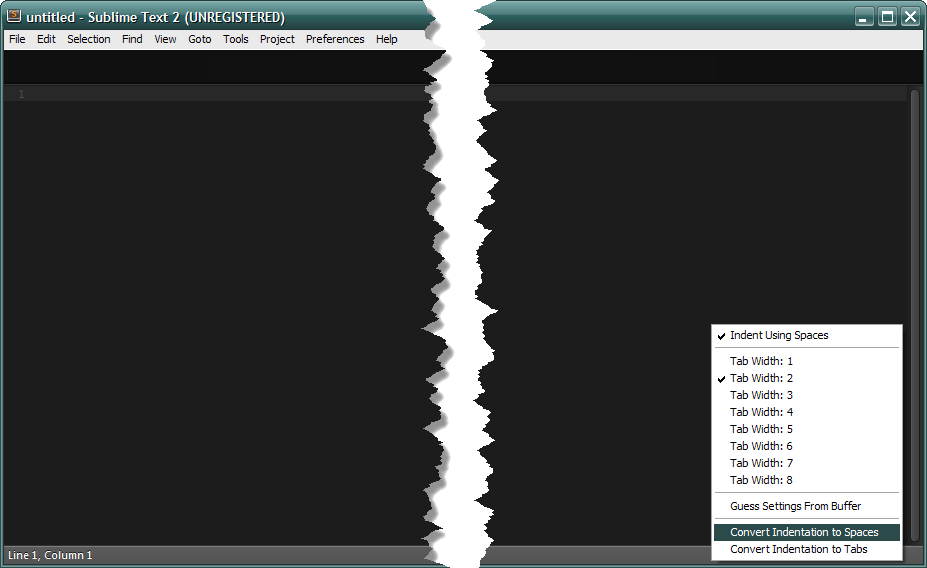
В правом нижнем углу находится кнопка-текст, при нажатии на которую открывается контекстное меню, представленное выше.
Первое - здесь можно выбрать размер табуляции - от 1
Tab Width: 1
1
Tab Width: 8
Если, к примеру, в текущем документе используется размер табуляции 1
4
1
2
1
4
1
2
1
4
1
2
Строка “Convert Indentation to Spaces” позволяет автоматически конвертировать всю табуляцию открытого документа в символы пробелов. Строка “Convert Indentation to Tabs” выполняет противоположную функцию - преобразование пробельных символов с табуляцию. При этом редактор выполняет данную задачу также автоматически, для всего документа, ничего выделять не нужно.
Самая верхняя строка - “Indent Using Spacing” показывает, какие символы используются в текущем документе для создания отступов - табуляция или пробелы. В моем случае - это символы пробелов. Это настройка, выставленная в Sublime Text для всех документов, открываемых или создаваемых. Достичь ее можно, отредактировав файл конфигурации редактора.
Редактирование файла конфигурации Sublime Text
Для редактирования настроек в редакторе предназначено два файла - один общий, с настройками по умолчанию (открыть его можно в меню через “Preferences - Settings - Default”).
Настроек там много, но все они хорошо документированы, так что не проблема понять, для чего каждая предназначена. Данный файл редактировать не рекомендуется, так как для пользовательских настроек предназначен еще один файл конфигурации - “Preferences - Settings - User”.
Вот в него я и буду писать свои личные предпочтения для работы в Sublime Text.
По умолчанию он почти пустой, в нем прописана только одна строка, в которой указана тема, использующаяся в оформлении редактора. Внесу туда настройки, которые хочу видеть (их все можно взять из общего файла, только изменить значение на то, которое нужно). Ниже картинкой показаны настройки, большинство из которых взято на просторах Интернета, то которые весьма полезны:
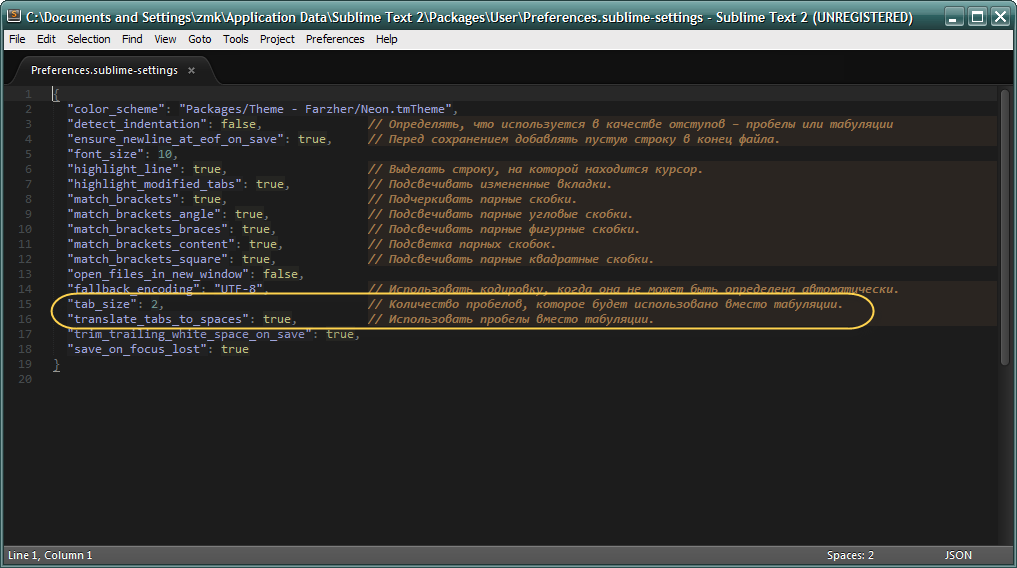
На картинке выделены две строки, которые отвечают за настройку величины отступа и символов, используемых для его создания.
Первая строка - 1
"tab_size": 2
1
2
Вторая строка - 1
"translate_tabs_to_spaces": true
Вот и все - этими двумя строчками я добился желаемого результата - мой Sublime Text в каждом новом документе делает отступы размером в два пробельных символа.
Если вернуться к остальным настройкам, представленным выше, то можно сказать, что почти все они очень и очень полезны.
Отдельно стоит отметить понравившиеся мне:
1
"trim_trailing_white_space_on_save": true
1
"save_on_focus_lost": true
1
"ensure_newline_at_eof_on_save": true
Все остальные перечислять не буду - они и так хорошо описаны (правда, на английском языке).
О темах для Sublime Text
Их существует большое количество - достаточно в поисковую строку менеджера пакетов ввести слово themes. В Интернете существует много обзоров тем, но в русскоязычных очень часто упоминается одна - 1
Soda
Такое впечатление, что русскоязычные пользователи все являются фанатами Mac OS X, ибо это тема “закошена” под такой стиль оформления.
Лично мне она не нравиться. У нее слишком яркая цветовая гамма. Когда по полдня рассматриваешь HTML или CSS код в Sublime Text, то начинаешь это чувствовать.
Моя любимая тема оформления - 1
Farzher
Она действительно имеет приятную передачу цветов, сами цвета приглушены (если даже выбран светлый вариант). Ниже приведу картинку с открытым HTML-кодом, расцвеченым в 1
Farzher Neon
На этом все.