В одной из предыдущих статей я описывал способ определения радиуса скругления элемента на макете Photoshop.
По прошествии некоторого времени мне стало очевидно, что вышеназванный обзор оказался неполным и с одной неточностью. В чем же заключаются эти два недочета?
В этой статье я попытаюсь исправить ситуацию. Тем более, что ответ на один из вопросов меня интересовал, скажем так, существенно. А вторая неточность может серьезно сказаться на качестве верстки. Точнее - на соответствие сверстанного HTML-шаблона своему оригиналу - psd-макету.
Оба недочета практически взаимосвязаны между собой, поэтому логично было объединить их описание в один материал. Итак, приступаю к разбору.
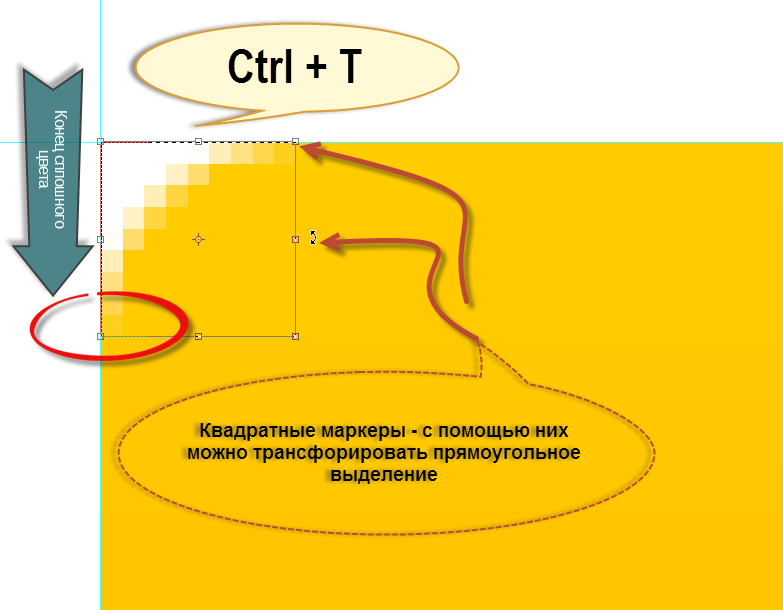
Первый вопрос. Трансформация прямоугольного выделения (Rectangular Marquee). Допустим, необходимо выделить какой-либо участок или элемент на psd-макете. Как обычно, выбираю инструмент выделения на панели Photoshop. И произвожу само выделение. Но бывает так, что после того, как выделение уже построено, его нужно изменить. Увеличить высоту или ширину. Или же наоборот - уменьшить. Каким образом нужно поступить в случае?
Все просто. Для изменения размеров выделения его нужно перевести в режим трансформирования. Проще всего это выполнить с помощью сочетания горячих клавиш Ctrl+T. Легко запомнить, Т - трансформирование.
Как только выделение переводится в режим изменения, внешний вид его меняется. Появляются квадратные маркеры на всех четырех углах и посередине вcех четырех сторон. Мышкой захватываю нужный мне маркер и тяну в необходимую сторону.
Чтобы легче было представить, как это выглядит на деле, достаточно взглянуть на рисунок “Трансформация выделения” ниже.
С первым вопросом разобрались. Приступаю ко второму. В чем же заключается неточность, которая может “сгубить” шаблон?
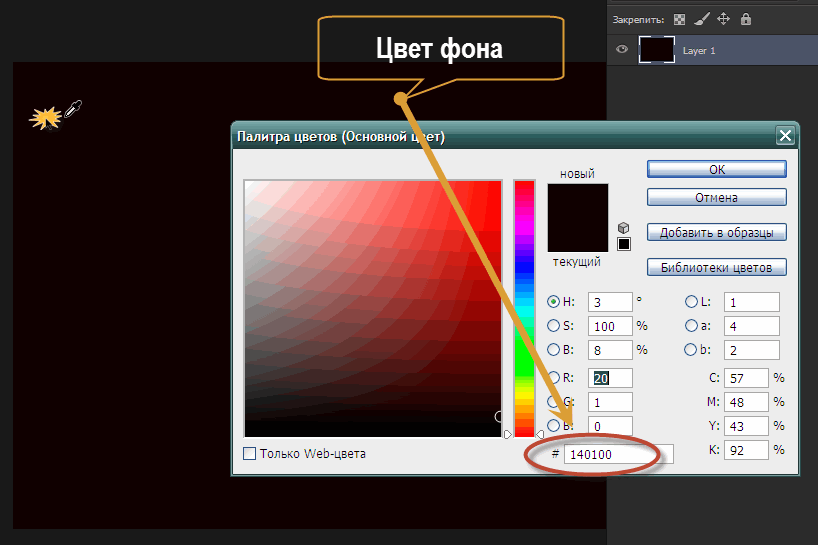
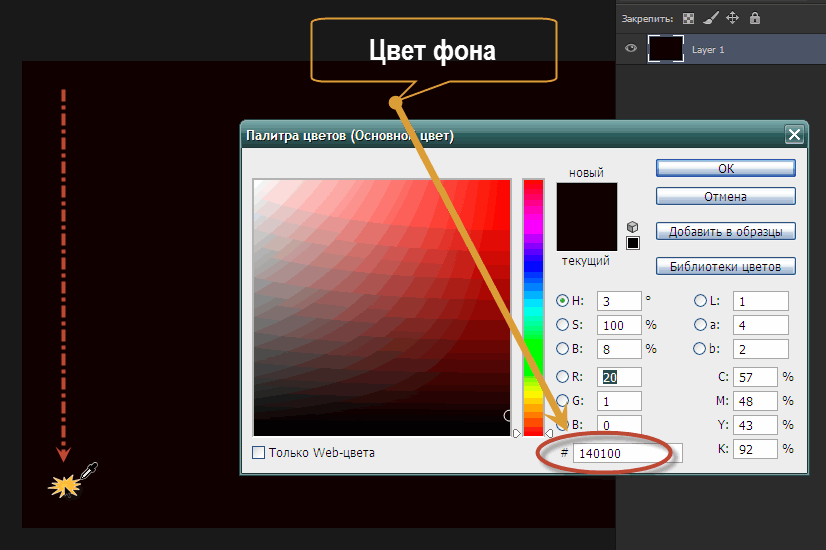
В неверно измеренном радиусе скругления. В предыдущей статье строился квадрат выделения для измерения радиуса скругления. Причем, углы квадрата должны были совпасть с точкой скругления элемента. Так вот, весь вопрос заключается в том, что точкой скругления должна считаться та, где заканчивается сплошной цвет и начинается цветовой переход.
Если максимально увеличить участок элемента, где нарисовано скругление, то попиксельно можно увидеть этот цветовой переход. Вся тонкость заключается в том, чтобы поймать эту точку.
В зависимости от цвета заливки, это может быть достаточно трудной задачей. Тут нужна внимательность и точность.
Ниже представлен рисунок, на котором есть ответы на оба вопроса:
На этом можно закончить этот краткий обзор.