Для веб-разработчика, и для верстальщика в частности, первые вещи, которые он обязан знать, это языки HTML, CSS, Javascript с библиотекой jQuery.
Желательно знание основ PHP, популярных CMS - WordPress, Joomla, Drupal. Обязательно знание основ работы в Photoshop, иначе просто не сможет верстальщик работать.
Но причем здесь командная строка Windows, скажете вы? Это системному администратору в его ремесле она необходима, чтобы создавать
1
bat
-файлы, через терминал управлять удаленными соединениями, создавать и настраивать локальные сети. Для чего же она нужна человеку, который работает с веб-приложениями?
Оказывается, нужна. Не вся ее мощь, не все ее DOS-команды - только самые распространенные и необходимые. А нужна при работе с препроцессорами CSS, такими как SASS или LESS.
Насчет LESS - это можно еще поспорить, а вот для SASS она понадобиться однозначно. Установка препроцессора SASS производиться через командную строку; процесс мониторинга также запускается через командную оболочку.
Так что давайте подтянем свои знания в этой области на тот уровень, который необходим. Ниже приведено краткое описание с примерами всех тех команд, которые могут потребоваться. Некоторые читатели могут сказать - а зачем плодить еще одну статью по командной строке Windows?
В Интернете и так таких статей пруд пруди! На это могу сказать одно - этот сайт является моей записной книжкой. И здесь я выкладываю записи по принципу: “чтобы не забыть”, “описать задачу и ее выполнение самому, чтобы лучше понять”. Ну, лирика закончена, приступаем к делу.
Горячие клавиши командной оболочки
Win+R - быстрый запуск командной оболочки;
Alt+Space - меню настройки командной строки;
F7 - показ списка введенных команд в оболочке;
1
cmd /f:on
- включение перебора директорий по сочетанию Ctrl+D и перебора файлов по сочетанию Ctrl+F; (очень полезное свойство - благодаря ему не нужно вручную писать имя каталога, куда необходимо попасть, достаточно найти его методом перебора).
Создание папок
1
mkdir sass
- создание новой папки sass в корне текущего диска;
1
md sass
- аналогично предыдущей (укороченный вариант);
1
md sass\verstka
- создание вложенных директорий;
1
md F:verstka\revoltz
- создание директорий в указанном диске;
Просмотр содержимого каталогов
1
tree
- показ дерева каталогов;
1
tree /f
- показ дерева каталогов с их содержимым;
1
tree F:sass
- показ “куска” дерева каталогов, начиная с указанного места;
1
dir
- просмотр содержимого текущего диска (каталога) в виде списка;
1
dir F:
- просмотр содержимого диска
1
F:
1
dir /p F:
- постраничный вывод содержимого диска
1
F:
1
type test.txt
- просмотр содержимого файла (расширение файла указывать обязательно);
Перемещение по каталогам и дискам
1
cd /d F:
- переход в корень диска
1
F:
(для меня, как бывшего линуксоида, странное и неудобное нагромождение с ключом)
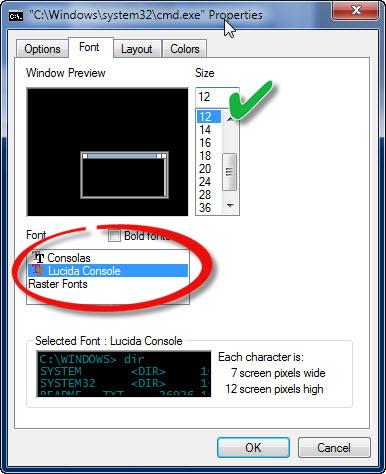
Для работы в командной строке также желательно ее настроить, облагородить под себя. Ибо изначально вид командной оболочки достаточно непригляден. Для открытия свойств окна терминала достаточно щелкнуть ПКМ на любом месте заголовка окна.
Затем перейти в свойства - окно с четырьмя вкладками.
Первую - “Options” - можно пропустить, там ничего особо интересного нет.
Вторая вкладка - “Font” - для настройки шрифтов. Лучше всего поставить шрифт “Lucida Console” и кегль 12:
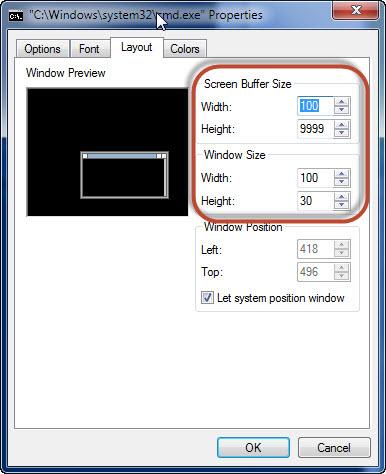
Третья вкладка - “Layout” - для настройки размеров окна. Наиболее удобные размеры приведены на рисунке:
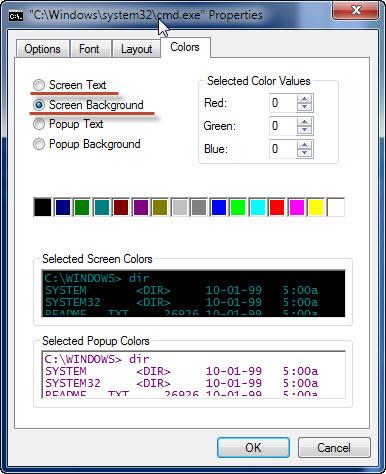
Четвертая вкладка - “Colors” - для настройки цветов фона, текста. Всплывающее окно (появляется по нажатию клавиши F7) также настраивается с помощью фонового цвета и цвета текста - но кто его использует? (можно оставить “как есть”):
Конечно, все настройки индивидуальны. Как говориться, на вкус и цвет все фломастеры разные. Поэтому рисунок ниже - примерный вид того, каким может быть настроенный терминал Windows:
В этой статье будем создавать меню-аккордеон с помощью jQuery UI.
Что такое jQuery, знают все - это библиотека Javascript. То есть, это собрание готовых модулей для самых разнообразный действий на сайте, таких как применение анимации, динамического изменения свойств HTML-элементов и многое другое. С помощью jQuery подобные действия можно “прикрутить” к страничке легко и быстро.
jQuery UI - это библиотека для библиотеки jQuery. Другими словами, если jQuery - это надстройка над Javascript, то jQuery UI - это надстройка над jQuery. Пирамида получается в некотором смысле этого слова.
Предназначение jQuery UI - создание интерфейсов пользователя на HTML-странице. UI - это аббревиатура User Interface (Интерфейс Пользователя), а именно - это меню навигации, вкладки, полоса прогресса, календарь, автопроверка вводимых данных и другое.
Меню-аккордеон можно сделать на чистом CSS, но сегодня рассмотрим самый простой и надежный способ - на Javascript, так как он заведомо будет работать во всех браузерах, если в них не отключена поддержка этого языка.
Первое, что нужно сделать - это набросать каркас HTML-страницы, то есть
Затем подключаем библиотеку jQuery и ее надстройку jQuery UI, причем делать это нужно в указанном порядке: сначала основная библиотека, затем ее надстройка. Так как мы будем делать меню со своими собственными стилями, то необходимо выполнить следующие шаги.
Переходим на страницу загрузки и здесь выполним компиляцию ядра и только необходимых нам модулей (возможностей) jQuery UI. Что это значит? Полный комплект библиотеки jQuery UI содержит в себе возможность создания самых различный интерфейсов - вкладок, ползунков, календарей, полос прогресса, автозаполнения и так далее. Нам же необходима только одна из них - меню-аккордеон. Зачем скачивать и использовать библиотеку целиком, когда можно применять в работе только малую ее часть? Выигрыш в загрузке страницы в окне браузера очевиден.
Другая, менее очевидная причина такого выбора заключается в том, что во время работы движок jQuery UI создает свои собственные классы стилизации для меню, в частности. Эти классы напрямую соотносятся с файлом стилизации, таким как
1
smoothness/jquery-ui.css
. Когда мы будем создавать правила CSS для нашего аккордеона, мы будет прописывать свои собственные классы. В итоге те классы, которые “вмонтированы” в связку “jQuery UI + Theme” будут только ненужным балластом и мусором.
Итогом всех вышеперечисленных умозаключений является следующая последовательность шагов. Заходим, как было уже сказано, на страницу и видим там три больших раздела: “Version”, “Components”, “Theme”. В первом разделе “Version” выбирается версия библиотеки jQuery. На момент написания статьи это
1
v.1.10.3
. Это нас устраивает, поэтому оставляем все как есть.
Переходим во второй раздел “Components”. Здесь из длинного списка модулей выберем только то, что нам необходимо. Но сначала снимаем галочку со всех выбранных по умолчанию опций - “Toggle All”. Пролистываем список вниз и находим нужную нам строчку - “Accordion”, ставим против нее галочку. Обращаем внимание, что автоматически активировались еще две галочки в подразделе “UI Core” - “Core” и “Widget”. Это два основных компонента ядра “jQuery UI”, без которых не будет работать ни один модуль.
Опускаемся вниз страницы в раздел “Theme”. Здесь по умолчанию выбрана тема “UI lightness”, это набор CSS-стилей для оформления меню-аккордеон, созданный командой разработчиков jQuery UI. Список готовых тем не ограничивается только этим файлом, на самом деле таких тем около 24, из которых можно выбрать понравившуюся. Помимо этого, можно воспользоваться визуальным конструктором “ThemeRoller”, перейдя по ссылке “Design a custom theme”. Но нас оба эти выбора не интересуют, так как мы будем создавать свои собственные стили. Поэтому в выпадающем списке тем данного раздела выбираем “No Theme”.
Осталось нажать кнопку “Download”, чтобы скачать скомпилированную библиотеку, которая будет носить имя jquery-ui-1.10.3.custom.zip и весить 461 Kb. Сравните - полная версия jQuery UI весит 2.37 Mb, разница ощутимая! Теперь распаковываем архив и вытаскиваем из него необходимые нам файлы, которые распихиваем в соответствующие им папки:
1
jquery-1.9.1.js
и
1
jquery-ui-1.10.3.custom.js
в папку javascripts (я буду создавать меню с помощью SASS/Compass). В папке css скачанного архива есть подпапка no-theme с CSS-файлом
1
jquery-ui-1.10.3.custom.css
. Пролистав го, я сделал вывод, что данный файл служит для подключения иконок и другого вспомогательного оформления будущего меню. Рискну оставить его в архиве и не использовать.
Подключаю полученные файлы библиотеки jQuery UI в
1
head
HTML-документа. Напоминаю, что я буду создавать меню-аккордеон с помощью SASS/Compass, поэтому название папок и синтаксис кода будет отличаться от “общепринятого”.
Создаем HTML-разметку для будущего меню аккордеон. Для чистоты эксперимента просто скопируем ее с сайта проекта jQuery UI, со страницы примера Accordion. Как написано на этой странице, разметка выполнена в виде заголовков третьего уровня
1
h3
и блоков
1
div
для того, чтобы контент был доступен на странице даже при отключенной поддержке Javascript в браузере пользователей.
Ниже приведена точная копия оригинальной разметки от разработчиков jQuery. Видим, что роль пунктов меню выполняют заголовки, а контент меню обернут в блоки
1
div
, внутри которых может располагаться все что угодно - текст, список, картинки. Принцип создания меню на основе h3 и div немного не стандарный, так как обычно такие меню строятся на основе маркированных списков ul.
<divid="accordion"><h3>Section 1</h3><div><p>
Mauris mauris ante, blandit et, ultrices a, suscipit eget, quam. Integer
ut neque. Vivamus nisi metus, molestie vel, gravida in, condimentum sit
amet, nunc. Nam a nibh. Donec suscipit eros. Nam mi. Proin viverra leo ut
odio. Curabitur malesuada. Vestibulum a velit eu ante scelerisque vulputate.
</p></div><h3>Section 2</h3><div><p>
Sed non urna. Donec et ante. Phasellus eu ligula. Vestibulum sit amet
purus. Vivamus hendrerit, dolor at aliquet laoreet, mauris turpis porttitor
velit, faucibus interdum tellus libero ac justo. Vivamus non quam. In
suscipit faucibus urna.
</p></div><h3>Section 3</h3><div><p>
Nam enim risus, molestie et, porta ac, aliquam ac, risus. Quisque lobortis.
Phasellus pellentesque purus in massa. Aenean in pede. Phasellus ac libero
ac tellus pellentesque semper. Sed ac felis. Sed commodo, magna quis
lacinia ornare, quam ante aliquam nisi, eu iaculis leo purus venenatis dui.
</p><ul><li>List item one</li><li>List item two</li><li>List item three</li></ul></div><h3>Section 4</h3><div><p>
Cras dictum. Pellentesque habitant morbi tristique senectus et netus
et malesuada fames ac turpis egestas. Vestibulum ante ipsum primis in
faucibus orci luctus et ultrices posuere cubilia Curae; Aenean lacinia
mauris vel est.
</p><p>
Suspendisse eu nisl. Nullam ut libero. Integer dignissim consequat lectus.
Class aptent taciti sociosqu ad litora torquent per conubia nostra, per
inceptos himenaeos.
</p></div></div>
Все готово для написания своих собственных стилей для нашего меню. Сброс стилей (reset) мне выполнять не нужно, так как Compass автоматически подключил его к моему проекту:
@import"compass/reset";
Устанавливаем самые общие правила для контейнера #accordion:
Вуаля - все готово! Меню работает на скрытие и раскрытие. Можно немного приукрасить навигацию, сделав заголовки активными - при щелчке мыши на нем содержимое будет сворачивается. При повторном щелчке на этом же заголовке содержимое меню будет вновь разворачивается. Выполняется это передачей нашему скрипту параметра
Все хорошо, но есть один небольшой недочет - по умолчанию скрипт задает для блоков
1
div
высоту
1
120px
. В третьем блоке у нас имеются два элемента - параграф
1
p
и список
1
ul
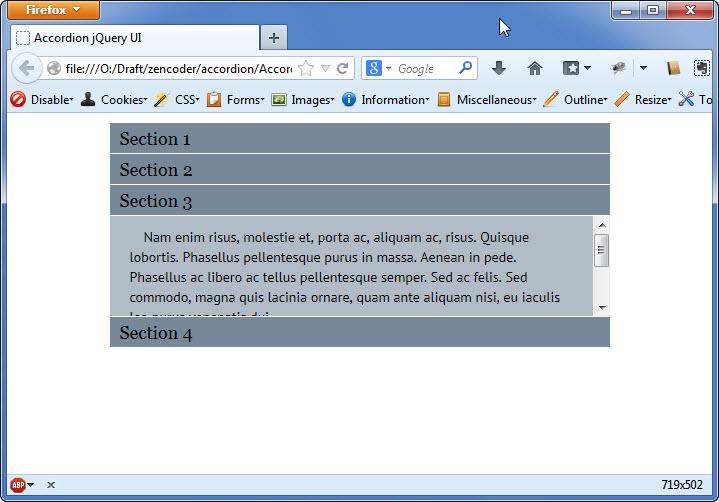
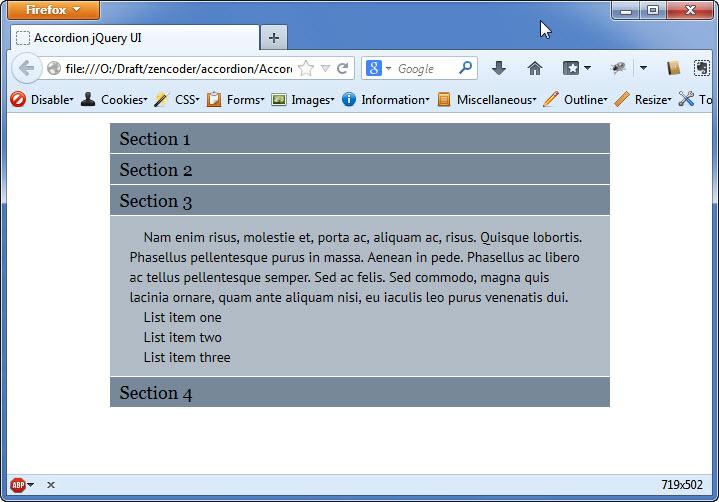
. При раскрытии этого пункта контент не вмещается по высоте и “налазит” на четвертый пункт. Аналогичная ситуация и с контентом четвертого пункта меню. Решение напрашивается само собой - нужно отрегулировать высоту для контента нашего меню.
Для этого нужно перейти по ссылке API documentation, где представлен список опций, методов и событий для меню аккордеон на jQuery UI. Нас интересует одна из опций - heightStyle, которая может принимать три значения:
1
fill
- высота всех блоков с контентом будет высчитана, исходя из высоты всей панели навигации (то бишь - меню-аккордеон). Для тех блоков, содержимое которых не вмещается, добавиться вертикальная полоса прокрутки;
1
auto
- непонятно, как оно работает. В документации сказано, что при установке данного значения высота для каждого блока содержимого панели будет высчитываться, исходя из высоты самого высокого блока. Однако, работа навигации с этим значением параметра
1
heightStyle
аналогична той, когда его вообще нет;
1
content
- высота каждого из блоков с контентом вычисляется в зависимости от величины его содержимого, то есть - подстраивается под контент.
Ниже представлены скриншоты меню аккордеон с вариантами значений
1
fill
и
1
content
для опции
1
heightStyle
:
Есть еще несколько интересных опций для меню на jQuery UI.
Опция
1
active
- какой пункт меню будет открыт по умолчанию в браузере. Номер пункта устанавливается через целое число, отсчет ведется с нуля.
Например, код:
active:2
… заставит браузер раскрыть третий по счету пункт меню.
Событие event назначит, при каком условии будет происходить переключение между пунктами меню. По умолчанию таковым является событие
1
click
, то есть щелчок мыши на пункте. Можно изменить событие на
1
mouseover
, что заставит скрипт открывать вкладку при наведении курсора мыши на пункт меню.
Можно сказать, что задача выполнена. Меню аккордеон на jQuery UI имеет еще достаточно опций и способов настройки, но здесь представлен самый простой и общий результат. Ниже приведен полный код созданного нами меню.
<!doctype html><htmllang="en"><head><metacharset="utf-8"><title>Accordion jQuery UI</title><script type="text/javascript"src="javascripts/jquery-1.9.1.js"></script><script type="text/javascript"src="javascripts/jquery-ui-1.10.3.custom.min.js"></script><linkhref='http://fonts.googleapis.com/css?family=PT+Sans'rel='stylesheet'type='text/css'><linkrel="stylesheet"type="text/css"href="stylesheets/screen.css"><script type="text/javascript">$(function(){$('#accordion').accordion({collapsible:true,heightStyle:"content"});});</script></head><body><divid="accordion"><h3>Section 1</h3><div><p>
Mauris mauris ante, blandit et, ultrices a, suscipit eget, quam. Integer
ut neque. Vivamus nisi metus, molestie vel, gravida in, condimentum sit
amet, nunc. Nam a nibh. Donec suscipit eros. Nam mi. Proin viverra leo ut
odio. Curabitur malesuada. Vestibulum a velit eu ante scelerisque vulputate.
</p></div><h3>Section 2</h3><div><p>
Sed non urna. Donec et ante. Phasellus eu ligula. Vestibulum sit amet
purus. Vivamus hendrerit, dolor at aliquet laoreet, mauris turpis porttitor
velit, faucibus interdum tellus libero ac justo. Vivamus non quam. In
suscipit faucibus urna.
</p></div><h3>Section 3</h3><div><p>
Nam enim risus, molestie et, porta ac, aliquam ac, risus. Quisque lobortis.
Phasellus pellentesque purus in massa. Aenean in pede. Phasellus ac libero
ac tellus pellentesque semper. Sed ac felis. Sed commodo, magna quis
lacinia ornare, quam ante aliquam nisi, eu iaculis leo purus venenatis dui.
</p><ul><li>List item one</li><li>List item two</li><li>List item three</li></ul></div><h3>Section 4</h3><div><p>
Cras dictum. Pellentesque habitant morbi tristique senectus et netus
et malesuada fames ac turpis egestas. Vestibulum ante ipsum primis in
faucibus orci luctus et ultrices posuere cubilia Curae; Aenean lacinia
mauris vel est.
</p><p>
Suspendisse eu nisl. Nullam ut libero. Integer dignissim consequat lectus.
Class aptent taciti sociosqu ad litora torquent per conubia nostra, per
inceptos himenaeos.
</p></div></div></body></html>
При оборачивании изображения в блок div внизу картинки возникает странный отступ.
Появляется он потому, что элемент img является строчным inline. При верстке часто возникает задача его убрать, так как он лишний и только портит дизайн. Решений данного вопроса существует несколько.
И пробуем пятью различными способами убрать этот отступ.
1. Сделать элемент img блочным
.block{display:block;}
2. Задать вертикальное выравнивание
Так как элемент img является строчным inline, то к нему применимо свойство vertical-align, как к любому строчному элементу. Мне такой способ нравиться больше всего:
.vertical{vertical-align:top;}
3. Сделать элемент плавающим через float
Задать для элемента img свойство float: left или float: right. Если элемент делается плавающим через float, то из строчного inline он становится блочным block.
И отступ также пропадает. Только надо не забыть добавить для контейнера div.image свойство overflow: hidden, иначе пропадет граница вокруг изображения.
Что и понятно, так как при float: left или float: right элемент “вырывается” из общего потока, становится плавающим:
.float{float:left;}
4. Сделать картинку таблицей
Для изображения задать свойство display: table:
.table{display:table;}
5. Задать высоту для блока
Для блока-контейнера div.image жестко задать высоту, равную высоте изображения. В моем случае высота картинки равна 230 пикселей, поэтому и для блока-обертки задаю такую же - 230 пикселей:
.height{height:230px;}
Все пять способов проверены мною и должны работать в реальности.
В предыдущей статье “Навигация breadcrumbs с помощью треугольников на CSS” описывался способ создания меню с помощью чистого CSS, без использования графики.
Метод всем хорош, за исключением одного - поддержка такого меню в старых браузерах сомнительна. Но при переводе этой статьи упоминалась ссылка на способ создания навигации с помощью графики.
Статья написана достаточно давно, но метод абсолютно рабочий. Автор статьи Veerle Pieters, а сам пост называется “Simple scalable CSS based breadcrumbs”. Ниже привожу даже не вольный его перевод, а вольный пересказ.
Несколько дней назад у меня стояла задача создать навигационное меню в стиле “хлебные крошки” (breadcrumbs) для сайта, над которым я работал. Я не думаю, что такое меню необходимо для каждого сайта, но в некоторых случаях оно очень полезно и практично.
Это послужило поводом для меня написать статью для своего блога. Тот пример, которым я хочу поделиться с вами, является очень простым, при его создании применяется только один графический файл. Остальная часть навигации создается с помощью CSS-кода.
Однако этот пример является как бы основой, которую можно расширять и применять на практике. Меню будет создаваться при помощи обычного маркированного списка
1
ul
.
Но сначала посмотрим на образец, с которым будем работать:
Меню достаточно простое, как и код, с помощью которого мы будем его создавать.
HTML код - маркированный список ul
<ulclass="crumbs"><li><ahref="#">Home</a></li><li><ahref="#">Main section</a></li><li><ahref="#">Sub section</a></li><li><ahref="#">Sub sub section</a></li><li>The page you are on right now</li></ul>
Все пункты меню имеют ссылки, кроме последнего - “The page you are on right now” (Страница, на которой вы сейчас находитесь). При работе над меню я задавался вопросом - является ли список наиболее подходящей структурой для создания меню? Я полагаю, что применение списка в этом случае не является строгим правилом, но мне кажется - это наиболее семантичный и правильный вариант.
CSS код - создаем стили для меню
Задаем общие стили для меню - убираем маркеры и обнуляем отступы в браузерах Firefox, IE:
ul, li {
list-style-type: none;
padding: 0;
margin: 0;
}
Далее для меню задаем класс с именем
1
crumbs
, устанавливаем границу толщиной в 1px и фиксированную ширину 30px:
.crumbs{border:1pxsolid#dedede;height:30px;}
Все “крошки” должны располагаться горизонтально, в одну линию, поэтому элементы
1
li
делаем плавающими через свойство
1
float:left
. Текст меню должен быть отцентрирован точно по вертикали, для этого устанавливаем для него значение свойства
1
line-height
равное высоте всего меню -
1
30px
.
Помещаем слева каждого пункта небольшое пространство для отступа с помощью
Придадим ссылкам небольшую анимацию с помощью псевдо-класса
1
:hover
и
1
:focus
. При наведении курсора мыши или получения фокуса с клавиатуры цвет текста ссылки будет меняться:
.crumbslia:hover,.crumbslia:focus{color:#dd2c0d;}
Результат нашей работы представлен здесь:
Примечание переводчика:
Автор статьи максимально упростил пример и сам код соответственно, насколько я понимаю. Дело в том, что на примере хорошо виден линейный горизонтальный градиент для каждого из пунктов меню. Однако в коде это никак отображено не было. Ну, не беда - разве это проблема создать линейный градиент на CSS3? Сама задача ведь выполнена!
Интересная статья по созданию навигации в виде “хлебных крошек” (breadcrumbs).
Такая навигация удобна и полезна для сайтов с большим количеством рубрик. Благодаря такой навигации пользователь сайта может не запутаться в содержимом, точно знать, где он находиться и легко перейти в то место, куда ему нужно.
Видов такой навигации может быть множество, все зависит от дизайна. Но принцип построения на CSS стандартный - с помощью списков
1
ul
.
Статья была опубликована на одном из моих любимых сайтов CSS-Tricks. Ниже привожу вольный перевод ее автора (Chris Coyier):
Вы уже знаете, как создавать треугольники на чистом CSS? Для этого просто генерируется блочный элемент с нулевой шириной и высотой, у которого имеется одна граница с цветом, а две смежные границы имеют прозрачный цвет. Такие треугольники применяются в самых разнообразных местах дизайна - например, для указателей в навигации.
Другое место их применения - невинные украшательства дизайна, не нарушающие его общую разметку. В счастью, это возможно благодаря псевдо-элементам, которые часто используются при их создании. Применяя
1
:before
,
1
:after
или оба сразу можно сгенерировать блочные элементы и с их помощью создать треугольники.
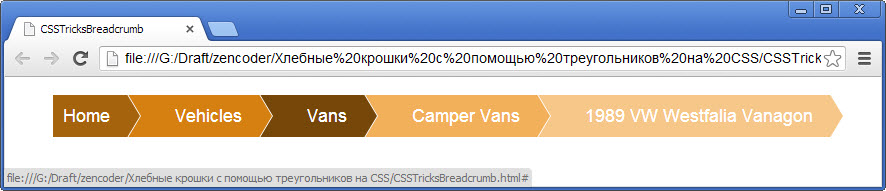
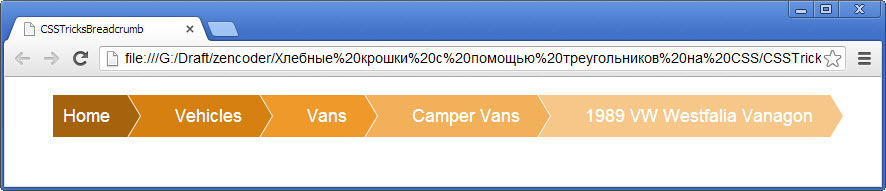
А вот последние можно применять для создания навигации в стиле “хлебные крошки”. Как выглядит одна из таких навигаций (чтобы иметь представление, что это такое), показано на рисунке ниже:
HTML разметка
Начнем создание такого меню с HTML-разметки, которая максимально проста и представляет собой обычный неупорядоченный список с классом breadcrumb:
В первую очередь убедимся, что наш список не выглядит, как обычный неупорядоченный список. Для этого уберем у него маркеры, сделаем его пункты плавающими влево и зададим самые общие стилевые правила для ссылок внутри этого списка. Обратите внимание на свойство
1
overflow
для всего списка в целом - он применяется здесь по двум причинам.
Первая - наш список должен иметь высоту. Контейнеры, которые содержат только плавающие элементы, схлопываются (
1
collapse
), что совсем не то, что нам нужно. Второе - когда мы будем создавать треугольники, мы сделаем их достаточно большими:
Для создания треугольника мы воспользуемся псевдо-элементом
1
:after
. Для него установим высоту и ширину, равную нулю; и абсолютно спозиционируем его на 100% влево, что означает - он будет располагаться у правого края своего блока родителя.
Затем сместим треугольник вниз на 50% и “вернем” назад на -50px для точного позиционирования по центру (это классический прием - перевод здесь). Есть только один момент, на который нужно обратить внимание.
Граница, которую мы создаем сверху, равна 50px, нижняя граница также равна 50px, а ширина левой границы равна 30px. Это сделано для того, чтобы треугольник получился более “плоским”, с не такой острой вершиной. Если мы сделаем левую границу равной остальным сторонам в 50px, угол треугольника будет слишком острый.
Так как верхняя и нижняя границы равны по 50px, то общая высота треугольника получается в 100px. Это гораздо больше, чем высота нашего меню, в котором высота шрифта
1
18px
и
1
padding-top: 10px
,
1
padding-bottom: 10px
. Однако, это хорошо, что треугольник больше высоты меню. Это означает, что у нас остается достаточно свободного пространства, чтобы “поиграться” с размером шрифта:
Все хорошо. Но на примере, который нужно воссоздать в коде, есть тонкая полоска шириной в 1px, идущая по краю треугольника. Чтобы “нарисовать” ее в CSS-коде, нам потребуется еще “поколдовать”, так как напрямую создать границу для треугольника не получиться. Ведь треугольник как раз сам и является границей!
Поэтому мы поступим по другому - создадим еще один треугольник, который поместим позади нашего первого и зададим для него белый фоновый цвет. По своим свойствам второй треугольник будет практически одинаков с первым, но создаваться будет с помощью псевдо-элемента
1
:before
.
Обратите внимание на важную вещь -
1
z-index
. С помощью этого свойства можно “тасовать” элементы
1
:before
и
1
:after
(точнее - созданные ими треугольники) в нужном порядке - какой треугольник над каким должен располагаться:
Теперь что касается цветовой заливки навигации. Так как пример имеет плавное изменение цвета элементов навигации, нам потребуются еще два замечательных CSS-свойства:
1
nth-child
и HSLa.
Чем полезно
1
nth-child
- можно задать цвета для различных элементов навигации без добавления дополнительной разметки в HTML-код;
Чем полезно HSLa - основываясь только на одном цвете, можно легко задать различные оттенки для элементов навигации.
Помимо этого, для первой ссылки мы уменьшим отступ слева с помощью
1
padding-left
, чтобы все элементы меню имели одинаковый размер; для последней ссылки совсем уберем цвет, сделаем некликабельной и вернем вид курсора по умолчанию. Все это мы выполним без какой-либо дополнительной разметки, с помощью псевдо-элементов
начинается с единицы, а не с нуля, как принято в языках программирования.
И наконец, состояния элементов навигации при наведении курсора мыши. Здесь единственная особенность - нам нужно задать цвет треугольника точно таким же, как и ссылка. Не проблема:
Назовите меня ленивым, но я не занимался вопросом проверки данного кода на кросс-браузерную совместимость. Я был слишком захвачен самой идеей создания меню “хлебные крошки” на чистом CSS, чтобы думать его практическом использовании. Но если вас волнует мысль о его поддержке более старыми версиями браузеров, то стоит обратить внимание на следующие вещи:
используйте для передачи цвета HEX-код вместо HSLa;
для каждого из пунктов меню
1
li
создайте свои классы, вместо использования
1
nth-child
;
для браузеров, не поддерживающих псевдо-классы
1
:after
/
1
:before
используйте схему создания навигационного меню, основанную на изображениях;
применяйте библиотеку Modernizr для определения поддержки браузерами тех или иных свойств (например, HSLa);
используйте дополнительные стилевые правила для IE.
Результат, созданный с помощью приведенного выше кода, показан ниже:
Эффект при наведении курсора мыши на один из пунктов меню:
[][3]
Эффект при наведении курсора мыши на меню навигации











 ][3]
][3]