С недавнего времени, всерьез занявшись написанием статей, столкнулся в небольшой трудностью. Заключается она в следующем: имеется материал в формате pdf, перевод которого необходимо выполнить. Естественно, в любой более-менее серьезной и качественной статье есть скриншоты, хотя бы один или два.
Что делать, если хочется создать точный - и самое главное - хороший перевод? Нужно, чтобы в этом переводе тоже присутствовали соответствующие теме скрины. И как поступить? Создавать свои собственные? Это довольно трудоемкий и длительный процесс. Конечно, речь не идет о какой-либо программе - в репозиториях Linux достаточно одной команды, чтобы ее поставить. А вот если дело касается дистрибутива? И если он “весит” около 2Gb? “Тянуть” и ставить его только ради скриншотов?
Вывод однозначен - надо “забрать” картинки из самого pdf-файла. Под OS Windows ответ напрашивается сам собой - Adobe Acrobat. Но если под Linux? Тоже выход есть! И даже еще аккуратнее - не надо мучиться с установкой гиганта Acrobat только для извлечения картинок с помощью последнего (например, у меня версия Adobe Acrobat 9.4 Pro “весит” 631Mb! Уму непостижимо - ведь это всего лишь одна программа!).
Итак, решаем проблему под Linux.
Первый шаг
Устанавливаем пакет xpdf. Программа стара, как мир и имеется в репозитории любого уважающего себя дистрибутива Linux. А об Ubuntu/Debian и говорить не приходиться. Там как в Греции - все есть!
$ sudo aptitude install xpdfШаг второй
Сама по себе “смотрелка” pdf-файлов xpdf нам в принципе не нужна. Интерфейс у нее убогий и не тянет на сравнение с тем же Okular. Но это и не важно. Мы ее не затем ставили. А ставили ради маленькой программы pdfimages, которая входит в состав этого пакета. Лишний раз проверим, так ли это. Посмотрим, есть ли она в системе после установки xpdf:
$ whereis pdfimages
pdfimages: /usr/bin/pdfimages /usr/share/man/man1/pdfimages.1.gzЕсть. Все ОК.
Шаг третий
Теперь, собственно, и приступаем к самому процессу извлечения. Переходим в директорию, в которой лежит наш “пациент” - jul2011.pdf:
$ cd /media/disk-2/works/journals/indian_hacker
$ ls
apr2011.pdf jul2011.pdf jun2011.pdf mar2011.pdf may2011.pdfИ “напускаем” на него нашу “крошку” pdfimages:
$ pdfimages -f 3 -l 9 -j jul2011.pdf nessusОпции команды описывать не буду - они, прямо скажем, примитивны и легко узнаются по стандартной команде -help. Здесь я применил только некоторые из них (и если честно сказать - почти все):
1
-f
1
-l
1
f
1
l
1
-j
Единственное, о чем стоит упомянуть - это следующее. У меня вызвано легкий ступор, ибо является неочевидным фактом: имя nessus в конце команды. Это имя может быть любым другим, на ваш выбор, но оно должно быть! Это своеобразная маска, по которой программа 1
pdfimages
$ ls nessus-003.jpg nessus-007.ppm nessus-011.ppm nessus-015.ppm nessus-019.ppm
nessus-023.jpg nessus-027.jpg nessus-000.ppm nessus-004.ppm nessus-008.ppm
nessus-012.ppm nessus-016.ppm nessus-020.ppm nessus-024.ppm nessus-001.ppm
nessus-005.ppm nessus-009.jpg nessus-013.jpg nessus-017.jpg nessus-021.jpg
nessus-025.ppm nessus-002.jpg nessus-006.ppm nessus-010.jpg nessus-014.jpg
nessus-018.jpg nessus-022.jpg nessus-026.jpgПрограммка 1
pdfimages
1
jpg
1
-j
Ну, нам ее излишняя старательность ни к чему (все, что она сохранила в формате ppm, является несущественным в данном случае), поэтому выполняем легким движением руки (точнее - пальцев):
$ rm *.ppmИ опять смотрим:
$ ls nessus-003.jpg nessus-010.jpg nessus-014.jpg nessus-018.jpg
nessus-022.jpg nessus-026.jpg nessus-002.jpg nessus-009.jpg
nessus-013.jpg nessus-017.jpg nessus-021.jpg nessus-023.jpg
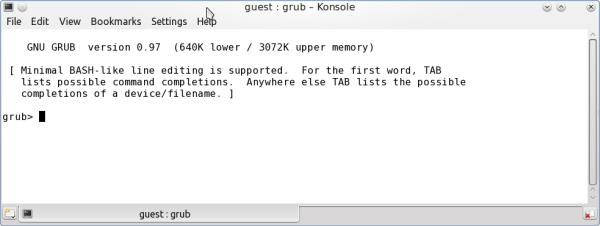
nessus-027.jpgСовсем другое дело! Как раз то, что нам нужно! Можно сказать, дело в шляпе. Посмотрим результат. Ведь интересно же - действительно ли все получилось? Пусть это будет nessus-027.jpg:

Резюме
Как вам такое решение “проблемы”? Для меня, так очень даже ничего! Изящно, красиво и быстро. И самое главное - результат! И тогда зачем возиться с программами под Windows, такими как например, специализированная утилита PDF Image Extraction Wizard. Да, имеет она красивый интерфейс. Но ведь фактически нужно платить только за него. Я уже не говорю о стоимости “монстра” Adobe Acrobat!
На этом все.